








The Semantic Gap in Art: AI Visual-Textual Alignment Study
A research analysis of how multimodal models like CLIP and ResNet struggle with narrative art vs. simple textures, quantifying the semantic gap.
The Semantic Gap in Art
Quantifying the Limits of Visual-Textual Alignment in Modern Architectures
Talih, Sluimer, Speh, van Goethem (UvA) | Summary Presentation
The Core Research Question
Do multimodal models actually "understand" artistic narrative, or do they merely match surface-level textures?
Operationalizing Art: The Semantic Binary
ADDITIVE (Simple)<br><span style='font-size:20px; font-weight:normal'>Meaning comes from visible objects.<br>Examples: Still-life, Landscape, Interior.</span>
NARRATIVE (Complex)<br><span style='font-size:20px; font-weight:normal'>Meaning depends on relationships & symbols.<br>Examples: Mythology, Religion, Historical.</span>
H1: Embedding Structure
Embeddings organize by 'Art Type' more strongly than Timeframe or School.
H2: Semantic Difficulty
Retrieval performance drops specifically for 'Narrative' art types.
H3: Texture Bias
ResNet architectures rely on surface texture; CLIP improves semantic alignment.
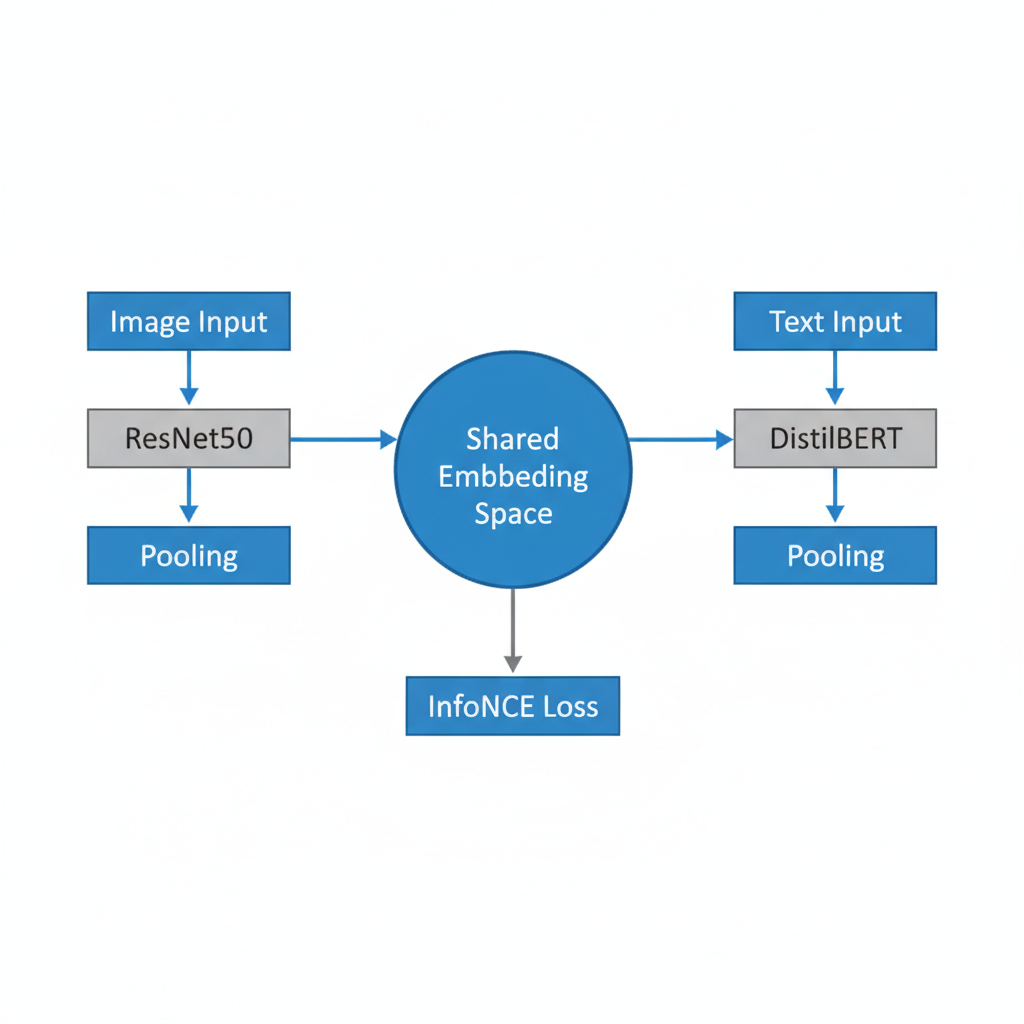
Experimental Pipeline (Contrastive Retrieval)
H1: The Embedding Space Organizes by 'Type'
Ratio: Intra-class Distance / Inter-class Distance (Lower is Better). Categories like School/Timeframe are indistinguishable from random noise (~1.0).
H2: Quantifying the Semantic Gap
Key Insight: 'Complex' narrative art is harder for ALL models. The gap factor is between 1.4x and 3.8x.
Qualitative Analysis: Additive Success
Query: Still-life (Simple). <br>Models successfully retrieve visually consistent images. The meaning is in the objects.
Qualitative Analysis: Narrative Failure
Query: Mythology (Complex). <br>ResNet retrieves 'Religious' or 'Historical' scenes. It matches colors/textures, not the story.
H3: The Texture Bias Problem
CNNs are architecturally biased towards local patterns (texture) rather than global relationships (narrative). Narrative art requires 'Cultural Context' which is invisible to a standard visual encoder.
ResNet vs. CLIP: Closing the Gap?
ResNet (Frozen/Tuned)
Strong texture bias. Narrative art scatters in embedding space. Adding BERT actually *hurt* performance (mismatch with visual features).
CLIP (Foundation Model)
Reduced gap (3.8x disparity vs ResNet's >2x, but better overall ranks). UMAPs show tighter clusters for narrative art. Understands 'content' better than 'form'.
Conclusion: The Gap Remains
1. VISUAL STRUCTURE: Embeddings organize naturally by Art Type (not School).
2. THE GAP: Explicit (Additive) art is solved; Symbolic (Narrative) art remains a failure mode.
3. TEXTURE BIAS: Without massive pre-training (like CLIP), models default to texture matching.
- ai-research
- computer-vision
- multimodal-learning
- art-history
- clip-model
- semantic-gap
- neural-networks