


Amazon Review Rating Prediction with NLP and Machine Learning
Discover how to predict Amazon star ratings using NLP models like XGBoost, Random Forest, and TF-IDF in this comprehensive machine learning case study.
Amazon Review Rating Prediction using NLP
Multi-Model Machine Learning Approach
Logistic Regression • Random Forest • XGBoost • TF-IDF • Streamlit
Course: Natural Language Processing
Problem Statement & Dataset
🎯 The Goal
Predict the star rating (1–5) from unstructured customer review text.
📊 The Dataset
Source: Amazon Cell Phones & Accessories Reviews<br>Format: JSON Lines<br>Key Feature: reviewText (Input)<br>Target: overall (1–5 Star Rating)
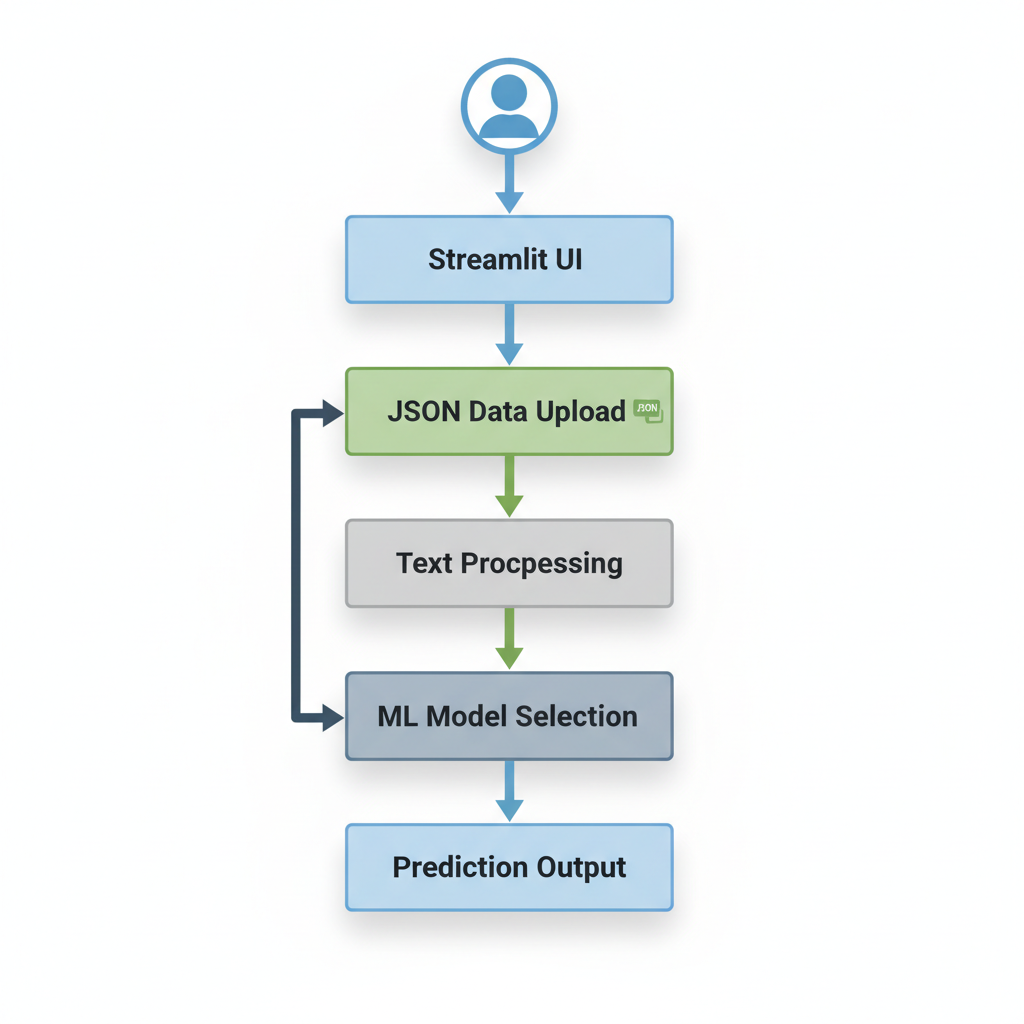
Project Architecture
<ul><li><b>Frontend:</b> Streamlit (Interactive UI)</li><li><b>Processing:</b> Pandas & Regex (Data Cleaning)</li><li><b>Vectorization:</b> Scikit-Learn TF-IDF</li><li><b>Modeling:</b> XGBoost, Random Forest, Logistic Regression</li></ul>
System Pipeline: NLP & ML Workflow
1. Load Amazon Review Data (JSON Lines)<br>2. Extract Phone Models (Regex)<br>3. Text Preprocessing (Clean & Tokenize)<br>4. TF-IDF Feature Extraction<br>5. Train-Test Split (80/20)<br>6. Train 3 ML Models<br>7. Evaluate (Accuracy & ROC-AUC)<br>8. Live Prediction
Data Loading & Dynamic Extraction
# Load JSON Data df = pd.read_json(uploaded_file, lines=True) df['summary'] = df['summary'].astype(str)
# Regex for Phone Models iphone_pattern = r'\biPhone\s*(\d+|[XxRr][Ss]?)\b' samsung_pattern = r'\bSamsung\b.*\b(Galaxy\s*)?S(\d+)\b'
✔ Enables dynamic model selection in the UI based on product extracted from review text.
Feature Engineering: TF-IDF
<b>TF-IDF (Term Frequency-Inverse Document Frequency)</b><br><br>• Converts text -> Numerical Vectors<br>• Penalizes common words (e.g., 'the', 'is')<br>• Highlights sentiment-rich terms
tfidf = TfidfVectorizer( max_features=800, stop_words='english' ) X = tfidf.fit_transform(model_df['reviewText'])
Prediction Models Implemented
1. Logistic Regression
Linear baseline. Fast & interpretable.
2. Random Forest
Ensemble of trees. Captures non-linear patterns.
3. XGBoost (Best Performer)
Gradient boosting. Optimized for ROC-AUC.
xgb_clf = XGBClassifier( objective='multi:softprob', n_estimators=200 )
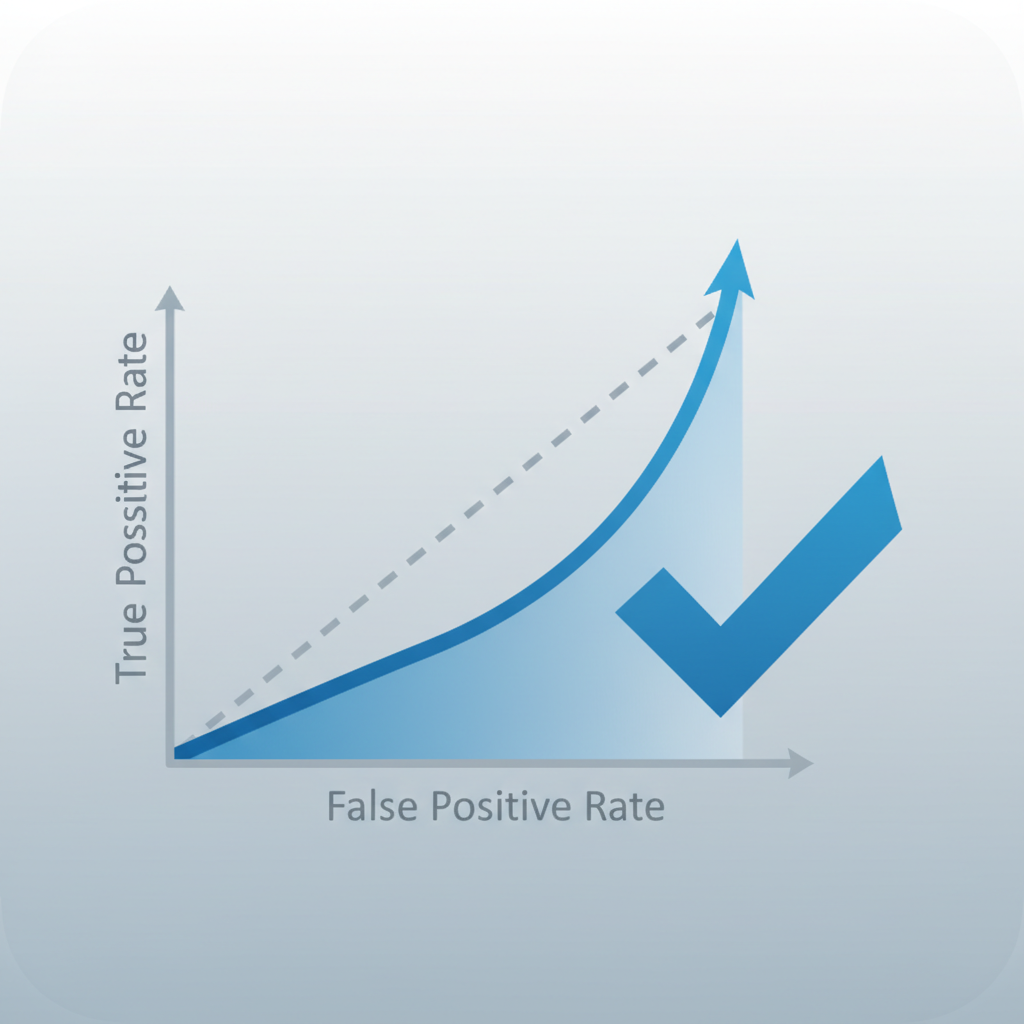
Model Evaluation Metrics
<ul><li><b>Accuracy:</b> Overall correctness.</li><li><b>ROC-AUC (Macro):</b> Critical for handling class imbalance (reviews are heavily skewed positive). Evaluates performance across all rating classes equally.</li></ul>
# Evaluation Code acc = accuracy_score(y_true, y_pred) auc = roc_auc_score(y_test_bin, y_proba, average="macro")
Results & Comparison
<ul><li><b>XGBoost</b> achieves the highest performance (ROC-AUC ~0.82).</li><li>Random Forest is a strong contender but slower to train.</li><li>Logistic Regression struggled with non-linear sentiment patterns.</li><li>Sentiment dominance: strongly positive/negative words drive predictions.</li></ul>
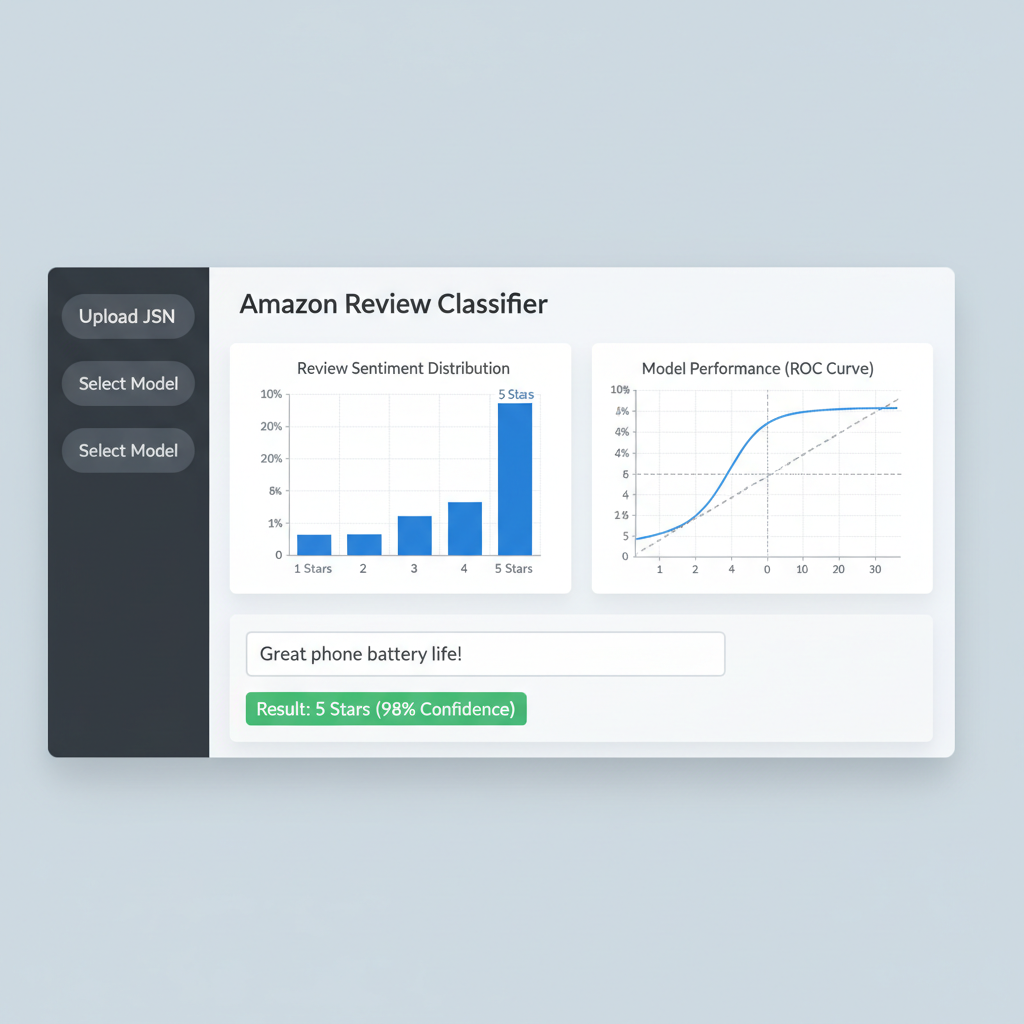
Live Prediction (Streamlit App)
# Real-time Inference vec = tfidf.transform([user_review]) confidence = xgb_clf.predict_proba(vec).max() prediction = xgb_clf.predict(vec)
<b>App Features:</b><br>• Upload Custom Dataset (JSON)<br>• Dynamic Phone Model Selection<br>• Visualization of Rating Distribution<br>• <b>Real-time</b> Confidence Scores for typed text
Running Application Demo
Streamlit Dashboard: Data upload, Model Selection, and Real-time Inference.
Conclusion & Future Work
✅ Key Takeaways
• TF-IDF effectively captures sentiment from short reviews.<br>• XGBoost outperformed linear models.<br>• Streamlit provides a rapid path from notebook to deployed app.
🚀 Future Enhancements
• Implement Transformers (BERT/RoBERTa) for contextual understanding.<br>• Aspect-based sentiment (e.g., Battery vs. Camera).<br>• Cloud deployment (AWS/Heroku).
- nlp
- machine-learning
- xgboost
- sentiment-analysis
- python
- streamlit
- data-science